
All-Physical Photo-Electrochemical Neural Network
Hu Lab Research Direction
Key Takeaway
Vision Statement
Our Work
We have developed a working framework for the design, training, and operation of AI hardware to be applied to upcoming experimentation
Impact
Our AI hardware innovation will lower the energy consumption, increase the computing speed, and improve the scalability of neural networks
Research Background
Initial Research Question
The rapid advancement of AI has driven an unprecedented demand for computational power, primarily relying on GPUs. However, the energy consumption of these systems has grown just as quickly, raising significant concerns about sustainability.
The pace of energy efficiency improvements in GPUs simply cannot keep up with the rising computational needs of modern AI applications.
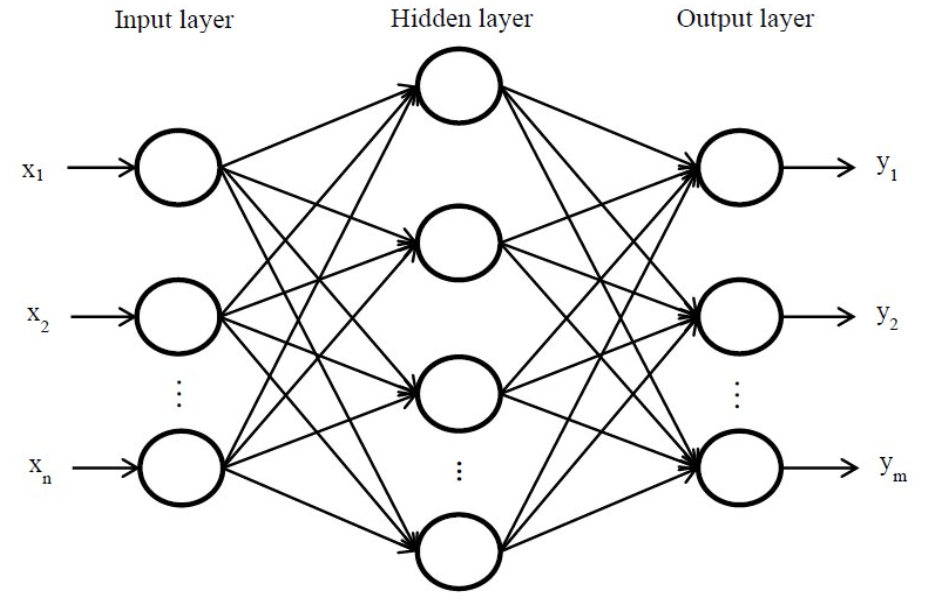
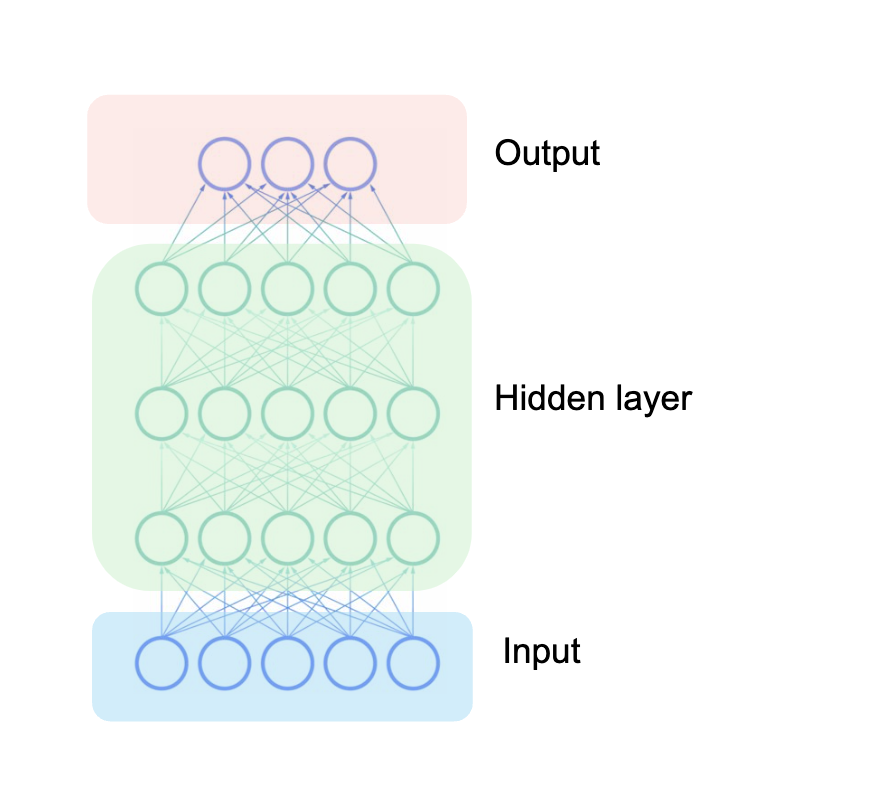
Principles of Neural Networks
A typical neural network’s architecture is composed of three main parts: an input layer, one or more hidden layers, and an output layer.
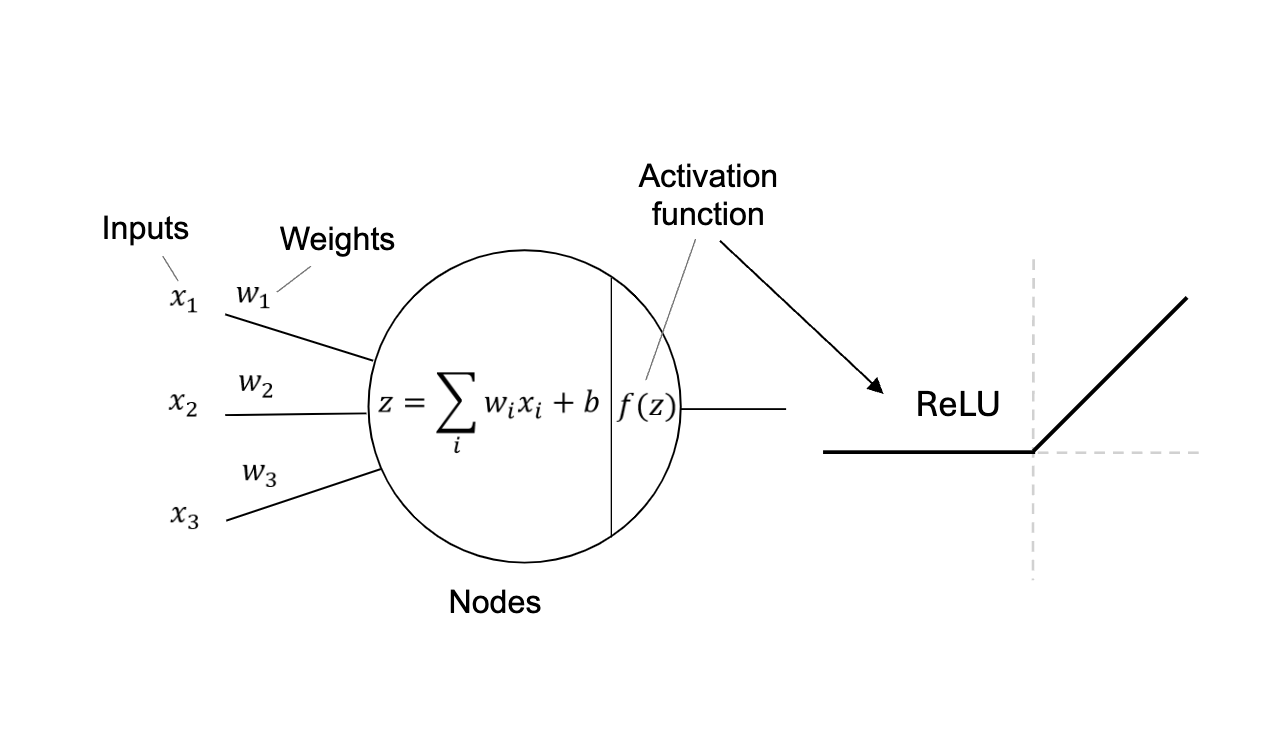
Information flows through these layers in a forward direction, with each connection defined by a weighted sum and a bias. These parameters determine the strength and direction of influence between neurons.
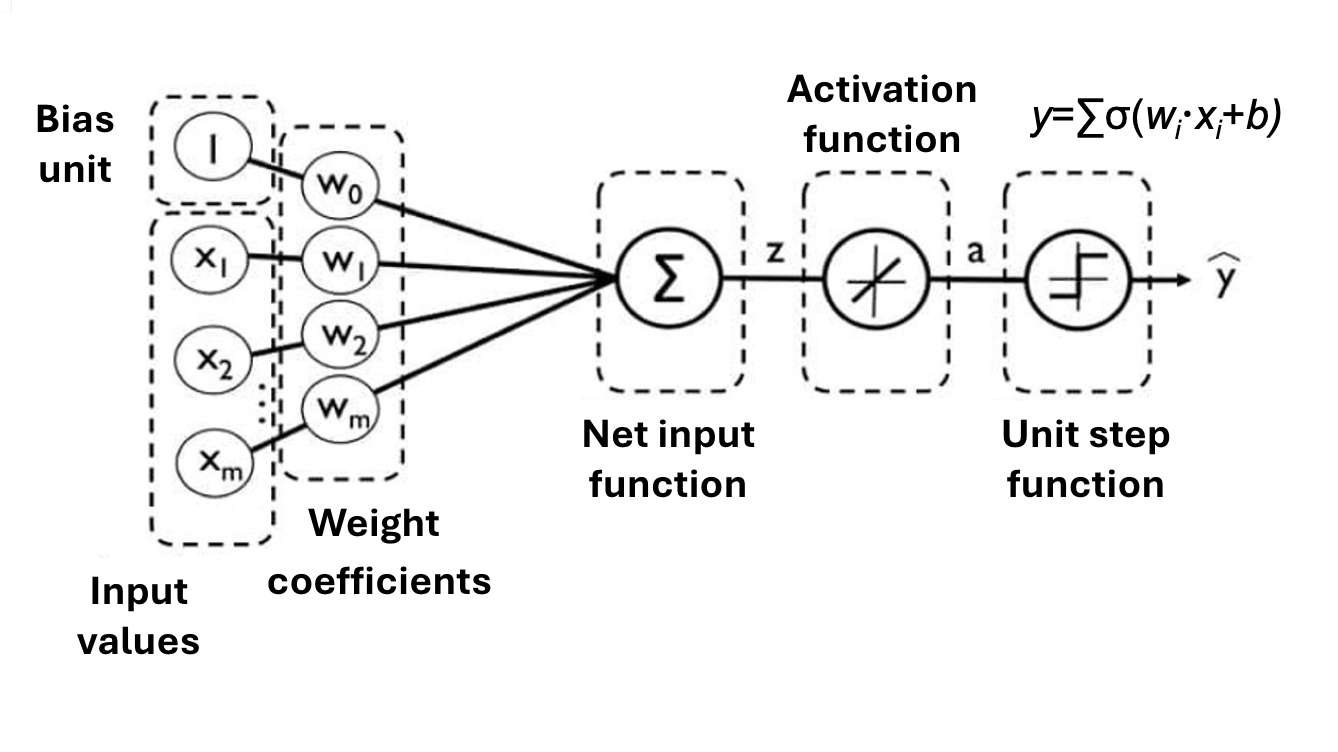
At each layer, the input undergoes an affine transformation—a linear combination of weights and biases—followed by the application of a non-linear activation function (such as ReLU, sigmoid, or tanh). This process enables the network to learn complex patterns and make accurate predictions.
Our Research Direction
To address the energy efficiency challenge, our research group is exploring innovative pathways for developing energy-efficient AI hardware. Recognizing that energy considerations are now central to the evolution of computing, we focus on the potential of physical neural networks to significantly enhance energy efficiency.
Inspired by the structure of artificial neural networks, we propose an approach using photo-electrochemical (PEC) chips. Our research aims to transform this concept into a viable technology, pushing the boundaries of both computational performance and sustainability.
Here are our main ideas for this AI hardware—much like building with LEGO blocks, each piece fits together to create something groundbreaking. If you’re interested, feel free to join us on this exciting journey!
Our Research
Test Case Scenario
As the first step—and a benchmark for our AI hardware—we propose a test case for identifying hand-drawn numbers.
By using image recognition as our benchmark, we enable fully analog computation, which operates at the speed of the electrochemical RC response. This approach offers significantly faster processing compared to traditional digital systems, demonstrating the potential for high-speed, energy-efficient AI performance.
In our system, images of hand-drawn digits are converted into signals applied to an n ×n electrode array, serving as the input for our hardware. As these electrical signals propagate through the hidden layer, they undergo transformations based on the network’s trained configuration.
At the output layer, signals are collected from 10 electrodes, each corresponding to the probability of one of the ten digits (0–9). The output electrode with the highest signal represents the most likely prediction, effectively identifying the hand-drawn digit.
Anatomy of AI Hardware
Our AI hardware shares a structural analogy with traditional neural networks but implements it using physical, photo-electrochemical processes instead of digital computation. This comparison can be understood by examining two main components: Input & Output (I/O) and the Hidden Layer.
In a traditional neural network, the input layer receives digital data—such as pixel values from an image—which are processed numerically within the network. Similarly, in our AI hardware, the input consists of electrical signals generated by converting images of hand-drawn digits into an n × n electrode array. Each electrode represents a specific portion of the image, allowing the hardware to directly interpret visual information in an analog format.
At the output stage, instead of producing probability scores through software calculations, the hardware collects electrical signals from 10 output electrodes. Each electrode corresponds to a digit from 0 to 9, and the electrode with the highest potential reflects the network’s prediction, effectively recognizing the digit based on the highest probability.
This entire I/O process happens without digital conversion, allowing for faster, energy-efficient computation.
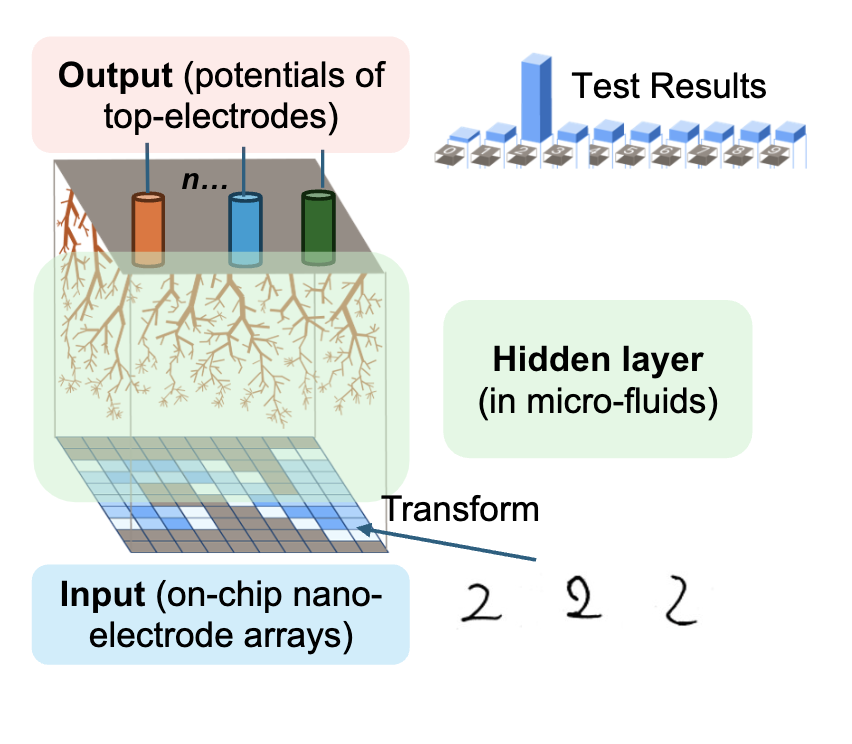
The hidden layer presents a deeper distinction between the two systems.
In traditional networks, the hidden layers adjust weights through backpropagation, applying non-linear activation functions such as ReLU to process input signals and minimize error using a loss function.
In contrast, our AI hardware employs a reversible deposition and dissolution process within a photo-electrochemical system to train the hidden layer. This dynamic mechanism allows for real-time adjustments and reconfiguration, mirroring the way traditional networks update weights during training.
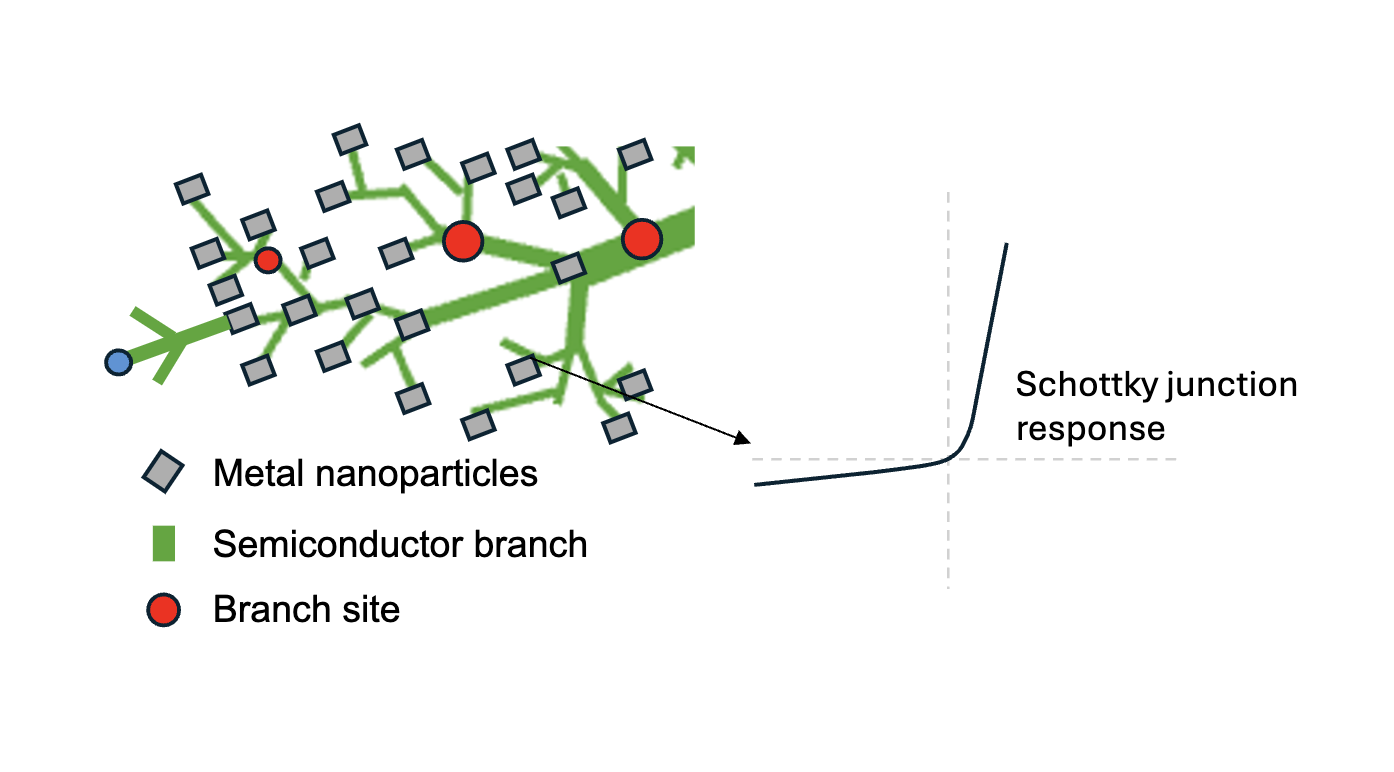
Non-linearity—essential for complex pattern recognition—can be achieved through metal-semiconductor (Schottky) junctions, which physically replicate the role of activation functions by introducing non-linear responses to the input signals.
AI Hardware Training
Our hardware training approach is inspired by the backpropagation algorithm used in traditional multi-layer perceptron (MLP) networks.
However, instead of adjusting weights digitally, we leverage photo-electrochemical deposition to physically form dendrite-like circuits containing Schottky junctions. These circuits are created in a directed manner, starting from the output layer and extending back toward the input layer, effectively mimicking the reverse signal flow characteristic of backpropagation.
Thanks to the reversible nature of photo-electrochemical deposition, we can also selectively dissolve these circuits. This process, which we refer to as detraining, allows us to weaken or remove specific connections, enabling fine-tuning and reconfiguration of the network.
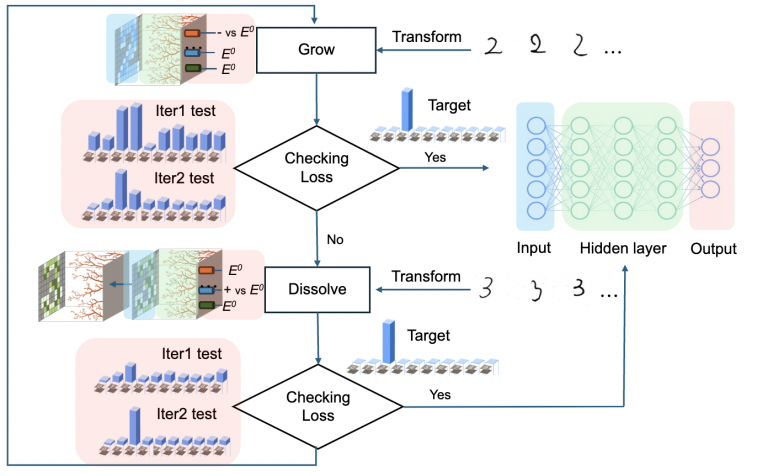
During training, we define a target function for the expected output and compute a loss function to measure the difference between the actual output and the target. This loss function then serves as an input for the detraining model, guiding the system to reduce errors by dissolving or reinforcing specific connections.
This dynamic, physical adjustment process allows us to iteratively minimize the loss, achieving efficient learning directly within the hardware itself—without relying on traditional digital computations.
Conclusion
By physically mimicking the structure and learning mechanisms of neural networks, our system can offer faster processing speeds while significantly reducing energy consumption through fully analog computation, which will address the growing challenge of energy consumption in modern AI systems.
Our approach has the potential to pave the way for a new generation of sustainable, high-efficiency AI hardware capable of meeting the increasing computational needs of the future.